Kubernetes Overview
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
From the Kubernetes docs:
Kubernetes is a portable, extensible, open source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
Kubernetes' Core Functionality
Service discovery and load balancing
Kubernetes can expose a container using the DNS name or using their own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable.
Storage orchestration
Kubernetes allows you to automatically mount a storage system of your choice, such as local storages, public cloud providers, and more.
Automated rollouts and rollbacks
You can describe the desired state for your deployed containers using Kubernetes, and it can change the actual state to the desired state at a controlled rate. For example, you can automate Kubernetes to create new containers for your deployment, remove existing containers and adopt all their resources to the new container.
Automatic bin packing
You provide Kubernetes with a cluster of nodes that it can use to run containerized tasks. You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources.
Self-healing
Kubernetes restarts containers that fail, replaces containers, kills containers that don't respond to your user-defined health check, and doesn't advertise them to clients until they are ready to serve.
Secret and configuration management
Kubernetes lets you store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configuration without rebuilding your container images, and without exposing secrets in your stack configuration.
Kubernetes Architecture
Kubernetes is made up of a few different components that make up a Kubernetes Cluster. A cluster is essentially just a collection of servers (or nodes) we can treat as a single pool of resources and run containerized workloads on and not care about the underlying node (though we can select which node we want the container to run on if we want). That's honestly all you really need to know, architecture-wise, to get started on K8s. But we'll go into a touch more detail for completeness.
A K8s cluster has a control plane and a data plane. The control plane is the brains and the data plane is the muscle. The control plane managers all the scheduling of objects; storing of important cluster metadata with a key-value store called etcd; and most important to us, contains the API Server that we communicate with from outside the cluster with the K8s CLI, kubectl. The control plate run on the Master Node. Typically we run K8s on a cloud provider's platform and they manage the control plane for us, so as mentioned, we won't need to worry much about it. We will be using AWS's Elastic Kubernetes Engine (Amazon EKS) in the next chapter, but Google Cloud Platform also has GKE and Microsoft Azure has AKS. The data plane is a collection of 1 or more Worker Nodes that have all the containers run on them. For the API Server to discover these nodes and treat them as part of the cluster for scheduling, they need to have a software (daemon) installed on them called kubelet. Again, typically the cloud provider can set these up automatically without us having to worry about it (E.g. using EKS's Managed Node Groups). Finally, they also need a container runtime such as Docker Engine installed on them to run the containers.
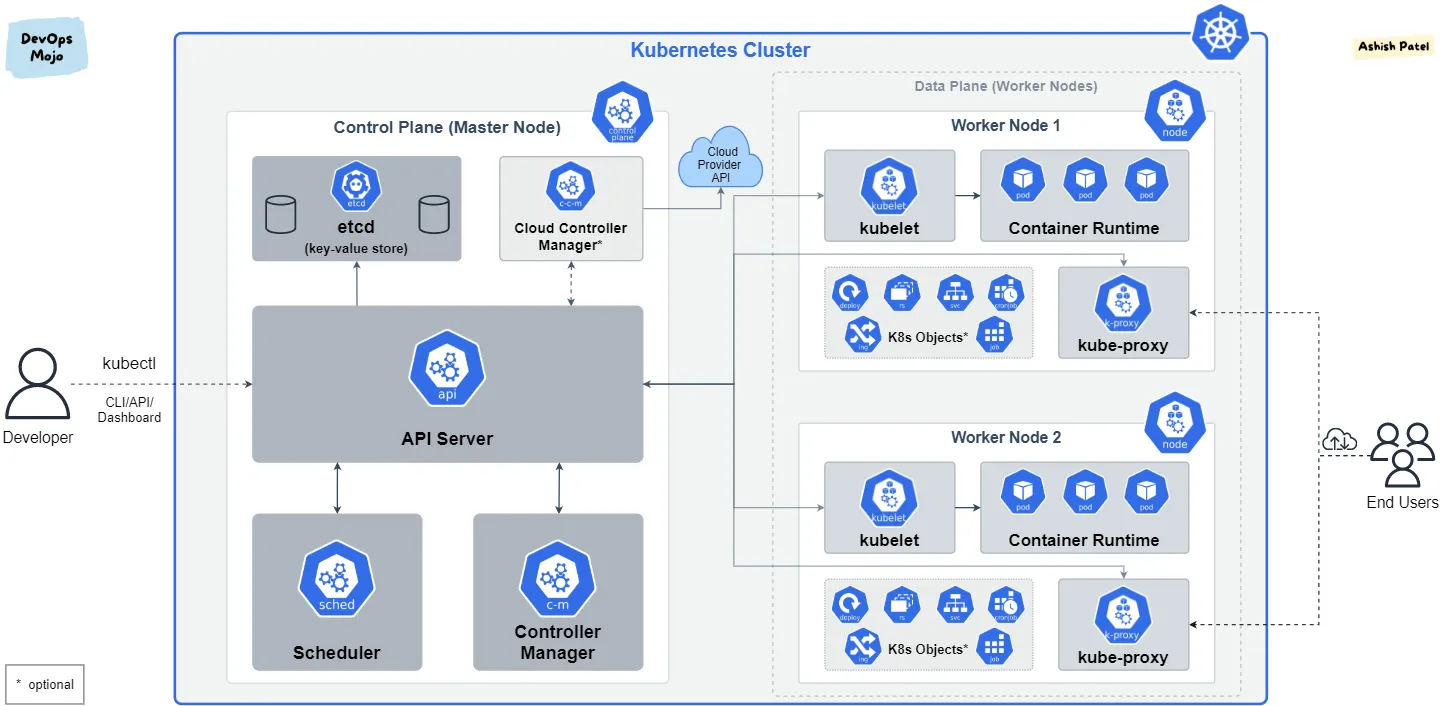
Kubernetes Objects
Just like a Dockerfile provides a definition for a containerized application, Kubernetes uses manifests (as YAML files) to describe the various objects that it manages. Kubernetes has a series of objects that are abstractions which manage or represent different functionality. There are many of them, but we'll look at the most important ones below.
Don't worry when you see all the YAML. Firstly, you absolutely don't need to remember them off by heart, it's more important to just get an idea of the concepts, and then you can Google the YAML when you need it to copy and paste and amend to your needs (Kubernetes has great documentation). Secondly, we're continuing with a bit more theory. We'll get our hands dirty in the next section, but Kubernetes is a big topic and it's important we get at least a foundation down first.
Pods
Pods are K8s' smallest unit of abstraction. K8s cannot directly manage containers. Instead, it has the pod concept as an abstraction on top of a container. You can actually have more than one container inside a pod, but this is rarely done. Typically, one pod has one container, and the pod describes what that container should be, which ports to expose (just like we did with docker run) and also some other metadata, such as labels (they are very useful as we will see), where to place the pod (in which namespace).
You should only place more than one container in a pod if it makes sense to do so. Such as a main app, and a side-car container that manages the app's log files for example. But otherwise, stick to one.
Below is an example of a simple pod manifest in yaml which would create a pod called my-pod that contains one container called my-container with the nginx:1.14.2 image (from Dockerhub) and exposes port 80. We will show in the next section how to actually use these manifests with kubectl.
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx:1.14.2
ports:
- containerPort: 80
Deployments
Actually, it's not often you create a pod yourself. You're more often interacting with another abstraction called a Deployment. A deployment manages the creation of pods. If you look at the template: section in the deployment manifest below, you can see it's very similar to the pod manifest above. This tells the deployment what type of pod you want to create, and then you have other details such as replicas that tell the deployment how many pods of that template it should create (3 identical nginx containers in the below example).
A deployment also manages the lifecycle of its pods; restarting or creating a new one if a pod stops working; keeping track of any updates and doing a rolling update to prevent down-time; undoing, or rolling back a update if you wish to, say, because of a bug it a newer version for example.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx:1.14.2
ports:
- containerPort: 80
There actually is another abstraction between the Deployment and the Pod(s) called a ReplicaSet (yes, Kubernetes is just abstractions all the way down). The replica set actually manages the replication of the pods (e.g. making sure there are 3 nginx pods and creating another one if one goes down). The deployment does the lifecycle management, such as updates and rollbacks. You rarely interact with a replica set however, they are created automatically by the deployment so we won't worry about them for now.
Services
Each pod has its own private IP address inside the cluster so pods can communicate with each other over http. The problem is, if a pod crashes or is removed for whatever reason, that IP address is no longer valid, and if a new pod is created, it's given a new IP, not the same as the old one. So if you hard-code the IP address of a pod in another pod's application hoping to make a request to it, we can't guarantee it will work forever. This is what a Service is for.
Services are an abstraction to help you expose groups of Pods over a network. Thanks to Kubernetes' DNS (Domain Name System), you can have a single service that provides a consistent address, which can route requests to the pods that it's linked to. The service is in charge of keeping track of the IPs of its pods, and which pods are delete and which are newly created. We don't have to worry about it, we can just direct our requests to the service.
There are three types of services: ClusterIP, NodePort and LoadBalancer. Despite the name of the third, they all load balance traffic to the pods that they're linked to. Just in different ways.
ClusterIP
This is the default type if you don't specify one in the manifest (I did below, just to be explicit). This is an internal service inside the cluster, and is used for pods to talk to each other. If in the same namespace you can simply use the name of the service in your request, e.g. curl https://my-service. If the service is in another namespace, or you just want to be explicit, you use the address <serviceName>.<namespaceName>.svc.cluster.local. So if you want to request a service called cool-app in the my-apps namespace from within the same cluster you can use curl http://cool-app.my-apps.svc.cluster.local.
NodePort
A NodePort is for exposing your services to outside the cluster and it simply routes traffic on a random port on the host node (hence the name) to a random port on the container. Useful for making your apps available to the public.
LoadBalancer
This creates an external load balancer on the cloud service you're using to route traffic to pods. Strangely, this is configured on EKS to spin up an Elastic Load Balancer on AWS, which is the old type of LB on AWS and no longer recommended. To get an ALB or NLB (Application Load Balancer or Network Load Balancer) you need the AWS Load Balancer Controller installed on your cluster, which we worry about for the time being.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
type: ClusterIP
ports:
- protocol: TCP
port: 8080
targetPort: 80
Jobs
Jobs are yet another abstraction over pods and are used to manage workloads that aren't meant to run forever like a web server. As the name implies, they're good for managing jobs, e.g. you have a pod that does some data extraction and you only need it to run once and then stop. This can also be done with just a pod definition manifest, but using a job has some extra features like managing retries, how long to wait before you start the workload, etc.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
There is also a CronJob object which manages jobs and can schedule them using cron, e.g. run this job daily at midnight.
Namespaces
Finally, the last object we'll look at for now is a Namespace. Namespaces provide an 'area' in which other objects can live. They can be used for organisation and tidiness, such as grouping all cluster monitoring apps in the monitoring namespace, so if you later want to execute a command that basically says 'give me all the pods in the monitoring namespace.
Namespaces can also provide security with a NetworkPolicy. The can work as a firewall for a namespace, where you define what traffic can go into a network and what can go out.
They're also useful for a logical grouping of objects, so if you apply something to a namespace, it can apply to everything in the namespace, such as resource limits. For example you could have a namespace per team - finance, marketing, and put limits such as max 8 GB RAM each, so that one team doesn't use up all the cluster's resources and prevent other teams from doing work.
There is a default namespace, and if you create an object without specifying which namespace to put it in, it will be created in the default namespace.
apiVersion: v1
kind: Namespace
metadata:
name: my-namespace
Okay, let's put this into practice.